| Row
| Name |
Size |
Last modified |
SHA1 |
| 1 |
AtomicCounter.html |
162k |
3324.1 days |
365b0c15031199490047e9ed7aa9d15e6514d550 |
| 2 |
Beertjes.jpg |
35k |
2601.6 days |
a9a76254b7bf861f24b227a108194b81a7550523 |
| 3 |
Blast_from_the_Past.jpg |
95k |
1953.8 days |
369ca4ef4e13e32be783301cb4298b5198738c6d |
| 4 |
Fonts.pdf |
1.8M |
1404.8 days |
920737b95056873716423be6dde1a21cca5e9029 |
| 5 |
IMAG0229.jpg |
808k |
4005.9 days |
7fc3f2504c63833cb4d2c8244e4f74d8971c1bbc |
| 6 |
IMAG0230.jpg |
707k |
4189.5 days |
278fd99618db4d2d7b476a6b777de4c1603e1831 |
| 7 |
Luna.jpg |
2.0M |
2601.5 days |
2c919dd6098dfaea5b48b3682e33592edf0c7a32 |
| 8 |
Model.compare.prof.json |
886k |
2441.8 days |
0a00ce5e6020bfb68ad191b0515bc54c5c030b96 |
| 9 |
SavaPro.pdf |
398k |
1404.8 days |
58ec3aaa002570bdca368ca210f0b599c8b203de |
| 10 |
blanked.pdf |
399k |
1404.8 days |
dddaefbdbc72cc3e382a1752bf28e8aeaf13174d |
| 11 |
boekje.jpeg |
118k |
1399.0 days |
636982dc6f67b9a87b4ab19f10603129438151b2 |
| 12 |
bonfire_to_taurus2.mp4 |
106M |
1192.5 days |
745eca234332ff634620faca403c2d837404558c |
| 13 |
catfight.mp4 |
10.2M |
2573.6 days |
1c7768e6e0fd75e26549eedb9bc8b63a6711d74e |
| 14 |
cda.jpeg |
227k |
1901.9 days |
9da9773253e2bf52c44820028c0f88bdb832dea4 |
| 15 |
computer-science.jpg |
111k |
2119.8 days |
82b630d52735152a37920534c7c13b9be51adadb |
| 16 |
cover.pdf |
405k |
1403.0 days |
4bf814238981c2ba22988a2d8194f203da19aac6 |
| 17 |
cxx.jpeg |
23k |
1953.8 days |
fcf9924f98e3c005fb7809c9b6641a214c4a4d75 |
| 18 |
emacs |
3k |
4020.8 days |
5acb25bbe774ad933fe2b05681338bc33c2574bc |
| 19 |
irc-quotes.png |
116k |
2493.0 days |
c610f6d2b652fafef188e5af5bdbd199befd9647 |
| 20 |
isoc11.pdf |
1.7M |
2104.6 days |
288049a9ab423f521f3783dbece627e58c387ee7 |
| 21 |
kabinet.jpeg |
136k |
1953.8 days |
128e2fc7fc001e0be191ab017f178a1ac135db89 |
| 22 |
latex.jpeg |
37k |
1953.8 days |
dcce040ed3d39594dcc916556effa2085d7ffac3 |
| 23 |
lockdown.jpeg |
291k |
1953.8 days |
ea73854bb0805adc63ff73e96bc335b9716a68cf |
| 24 |
lockdown.png |
546k |
1953.8 days |
926f215463f7e948b2dbffec445e0b5d24caa9c8 |
| 25 |
lucky.mp4 |
1.3M |
1955.9 days |
401556adec465f234c83f50d0a9070d0428e9a66 |
| 26 |
merijn.jpg |
147k |
1812.8 days |
0479bd074b7063e8016fbc6c9fb1cf65d6d0afe1 |
| 27 |
mu.png |
15k |
2021.8 days |
df305d4203c5cb2e0be65e427aa66f621f206058 |
| 28 |
opus-magnum.gif |
9.5M |
1989.9 days |
e9bb505f18a48e30f914c4d06b252212e9776cd9 |
| 29 |
panther-princess.jpg |
1.7M |
2715.9 days |
ebfec491d7cb589e4de1854c0e0d30df192f057d |
| 30 |
politics.jpg |
100k |
1953.8 days |
7015b44cc8e3d4427c51ea98a664f601eaa7fdb8 |
| 31 |
pytrilinos.tar.gz |
20.6M |
1853.9 days |
7c410318afc31a68801a04c470e5ada238f6eb22 |
| 32 |
same-picture.jpg |
229k |
1953.8 days |
d3e9aa2f051c7cf9eae26fd25f1c54b6c50dd499 |
| 33 |
samenvatting.pdf |
54k |
1409.7 days |
e8e01a8ffbd90d8d5fad51adebe6cdefef06ed23 |
| 34 |
screenshot1.png |
864k |
1950.8 days |
b2aea6f3cca21023c9cc321bd7b2bce59c9c9d07 |
| 35 |
screenshot2.png |
719k |
1950.8 days |
1282f5d34342af98aae243466b9c7d074d2bc061 |
| 36 |
screenshot3.png |
1.5M |
1950.8 days |
f686194db8c07bc3d573c26b3d40266b30793220 |
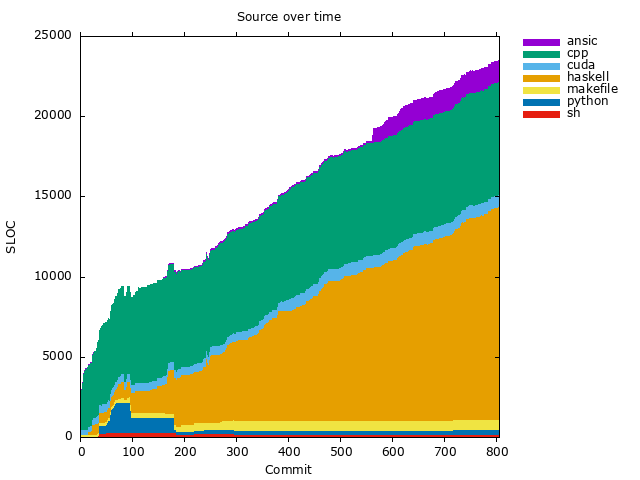
| 37 |
sloc-commits.png |
14k |
2120.9 days |
3bcb2192a053b798bfb3abcf3016036a016ad353 |
| 38 |
sloc-time.pdf |
22k |
2115.6 days |
550fd94e732ea35104fda81f2b8bc401f0520192 |
| 39 |
sloc-time.png |
14k |
2120.9 days |
288d980ab9bf52b455cd8de9e67f46aa22e08557 |
| 40 |
sync-threaded.txt |
6k |
3316.1 days |
b6c14ba106995f0c4263643390d8149b1e99324a |
| 41 |
sync.txt |
6k |
3295.2 days |
4d9b10e3c879ec8d1685aaf1f65e92e70d847962 |
| 42 |
thats the joke.png |
205k |
1953.8 days |
d3ddf733a65a0df3b544ae26c14ffdce492884be |
| 43 |
uninterested-coworker.jpg |
3.0M |
2249.0 days |
0c6a6a34817df42830f745118bb3db0b97b4501d |
| 44 |
unsolved-mysteries.jpeg |
219k |
1743.0 days |
d9878ca359beb996b25313a75011c32620451665 |
| 45 |
what-are-you-supposed-to-be.jpg |
71k |
1953.8 days |
ff5e74878d1149f86770aca1f6ad1818646304c1 |
| 46 |
why are you booing me.png |
800k |
1953.8 days |
647417ed57973df0f3a710da82a3c928b9ef478d |
| 47 |
wiensschuld.jpeg |
172k |
1953.8 days |
63c0f50c3af678536a74e46302df3c9c86e329ee |
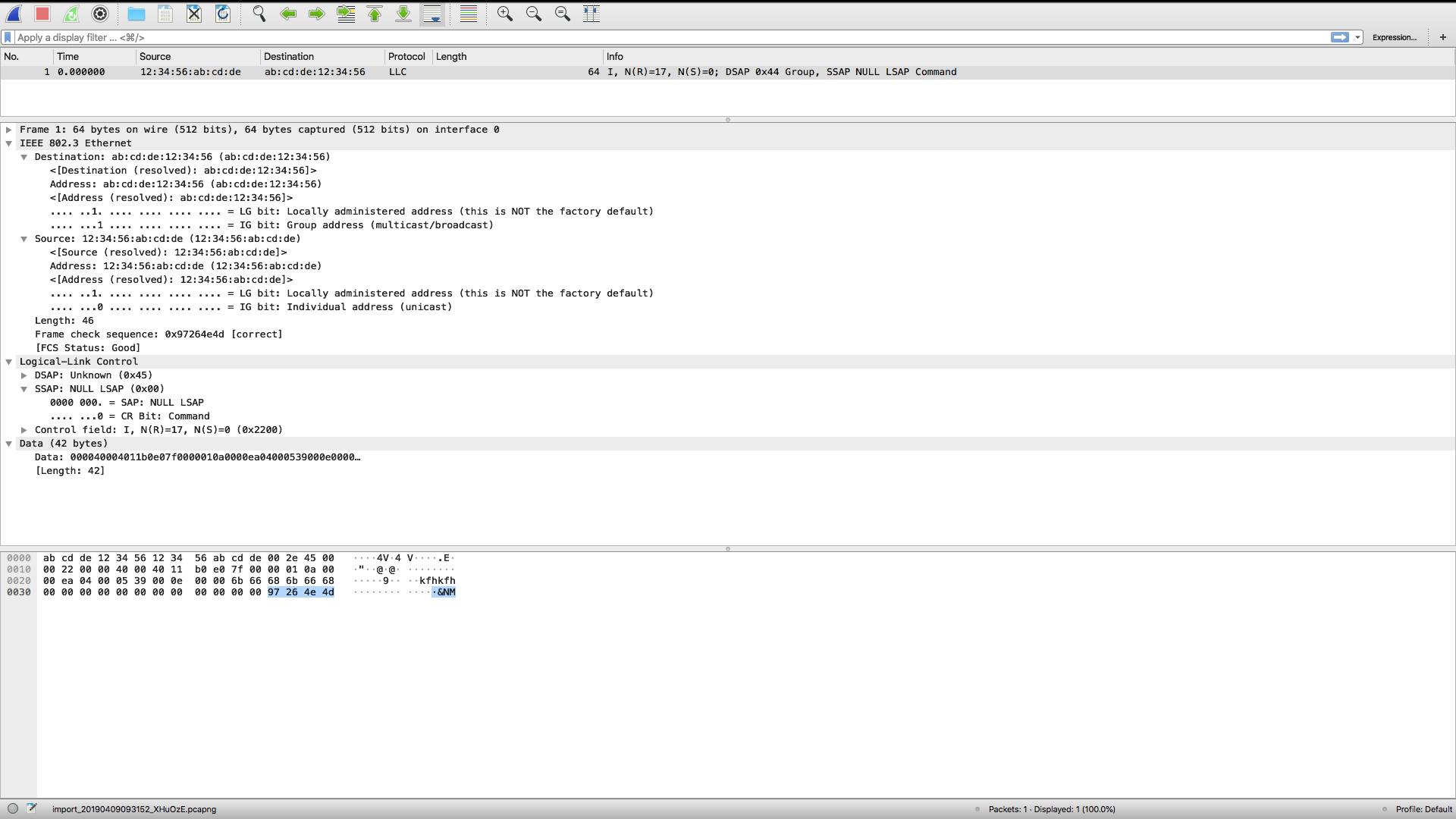
| 48 |
wireshark.png |
181k |
2626.1 days |
81390e256202852af8a3d69eb42d5e08df15c3af |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}